
A Tale of ZFS’ Success
ZFS is great. We hear it all the time, but you hope you will never need to utilize any of it’s advanced data-protecting features. I recently went through a series of events which makes me truly grateful for ZFS. This is a real world example that would have gone horribly different if I wasn’t using ZFS.
It’s Wednesday April 29th, 2015. I get home from work at about 6pm, fire up my workstation and tend to some emails. I look down and see the HDD LED on my file server, tesla, is solidly lit. All normal; today is a Wednesday and tesla started a scheduled ZFS scrub at 2am, which probably won’t complete until Thursday morning. I SSH in to check to see it’s progress and notice something new in the output of zpool status (serial numbers have been redacted in all the screenshots):

Some data was silently corrupted and repaired on one disk. To some this might not seem very odd, this happens a lot on some systems, but in over 2 years with this server, I’ve never seen this before. I immediately checked the SMART on the disk with corrupt data and found that 36 sectors were unrecoverably errored and the disk had 1091 pending sectors for reallocation. I was a little concerned, but in the past I’ve had several disks in other machines get a few bad sectors without any further issues for the rest of their lives.
I monitored the disk over the next few days and watched as the stats got worse:
- 04/30/2015, reallocated sector count: 592, pending reallocation count: 7640.
- 05/02/2015, reallocated sector count: 592, pending reallocation count: 7744.
- 05/04/2015, reallocated sector count: 592, pending reallocation count: 7816.
- 05/05/2015, reallocated sector count: 600, pending reallocation count: 7848.
My first thought was that this could be one of two cases. The first is that there is a bad portion of the disk which is slowly getting flushed out. The second is that there is a mechanical failure which is manifesting itself as read errors. I made a simple decision; if the disk has more serious issues during next week’s scrub, I will replace the disk. I had gone out earlier that week and bought a new disk because they were on sale, so I could replace the hot spare if need be.
Wednesday comes along and after work I come home to find this:

Well, I guess my decision is made. Time to replace the drive now and investigate later. I replaced the drive with the hot spare and the resilver began.


After detaching the bad drive, the pool looks good again.
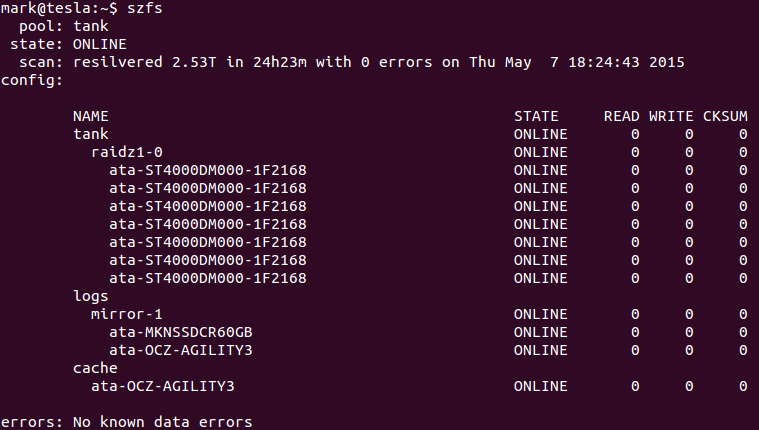
The job isn’t over yet though. Time to replace the bad drive with a new one to act as a hot spare. Doing this requires shutting down the server because the case does not have hot-swap bays. After replacing the drive and logging in, I’m faced with a terrifying sight. I don’t have a screenshot of this one because I was a little in shock. 3 vdevs were unavailable, and the pool was degraded. The drives were on different controllers, so the only thing I could think of was that some cables had come loose in the drive replacement. So I promptly shut down the server and opened it up again. On one drive, the power connector was slightly askew, but the other 2 had no signs of issue, so I just unplugged and plugged them back in at both ends.
At this point I was unsure of what would happen when I rebooted the server. Would ZFS be able to reassemble the pool now that the vdevs were reattached? Would I have to resilver the entire pool again? The only way to know was to power it up.

Now that’s impressive. ZFS resilvered only the changed data and the pool is back online again.
This series of events isn’t that uncommon, but the outcome would have likely been very different if I was not using ZFS. First of all, without ZFS I likely would not have been able to detect the silent corruption on the disk when I did. I would have eventually noticed as there were errors in the kernel log and SMART logs, but that could have been days or weeks later, after more damage had been done. Even if I knew there were errors, other implementations of RAID wouldn’t have been able to correct them. My best bet would have been to remove the disk entirely and rebuild the array from parity and hope that the parity was valid. If upon replacing the bad drive the cables had come loose as they did in my adventure, the array would most likely be destroyed. Most RAID implementations will want to resync a disk completely upon it disappearing for any period of time. The loss of 3 drives would mean that almost any RAID implementation would not have enough data to rebuild.
Leave a Reply